Introduction and Goals
VYGA is a cross-chain aggregator platform that pools leading and curated digital collectibles, digital art, Web3 gaming, and Metaverse projects. The primary goal is to provide an extended target group of "physical world" consumer brands with easy and convenient access to the "BEST OF WEB3." Additionally, it aims to facilitate product and project discovery in Web3 commerce.
MVP Goals
- Aggregate selected content from different networks (cross-chain content).
- Enable users to find content (search function).
- Develop AI-supported functionalities to ensure updated content and start developing a VYGA-owned index score for curation.
- Integrate with Hedera blockchain and Hashpack wallet for secure transactions.
- Train and deploy AI models on AWS for content curation and search optimization.
- Prioritize HBAR results in search functionalities.
- Implement rebranding requirements for the user interface (UI).
- Ensure compliance with data privacy regulations and financial transaction laws.
Executive Summary
VYGA is a cross-chain aggregator platform, pooling leading and curated digital collectibles, digital art, Web3 gaming, and Metaverse projects. The goal is to provide an extended target group of “physical world” consumer brands with easy and convenient access to the “BEST OF WEB3” and further to facilitate product/project discovery in Web3 commerce.
VYGA will aggregate and curate content from multiple networks, focusing on digital collectibles, digital art, Web3 gaming, and Metaverse projects. By leveraging AI-supported functionalities and automated processes, VYGA will provide up-to-date and curated content. The integration of advanced search capabilities, including prioritization of HBAR results, will enhance user experience and facilitate discovery in Web3 commerce. Integration with Hedera blockchain and Hashpack wallet will ensure secure transactions, while compliance with data privacy and financial transaction laws will be strictly maintained.
The MVP goals include aggregating selected content from different networks, enabling users to find content through a search function, and developing AI-supported functionalities to ensure updated content and start developing a VYGA-owned index score for curation.
Problem Statement Overview
VYGA aims to address several critical challenges in the Web3 space, including:
- Fragmentation Across Blockchain Networks: The Web3 ecosystem is highly fragmented, with content and data distributed across multiple blockchain networks. This fragmentation creates barriers for users who want to access, aggregate, and analyze data from different networks seamlessly.
- Security Concerns in Decentralized Environments: Decentralized platforms often face unique security challenges, including safeguarding user data and preventing unauthorized access to sensitive information. Ensuring secure transactions and data integrity across multiple blockchain networks is a significant challenge.
- Scalability in a Growing Ecosystem: As the adoption of Web3 grows, platforms must scale efficiently to handle increased user activity, larger datasets, and more complex operations without compromising performance.
- User Experience and Accessibility: Providing a responsive and intuitive user interface that can effectively handle the complexities of Web3, including real-time data aggregation and cross-network interactions, is crucial for widespread adoption.
- Compliance with Evolving Regulations: The regulatory landscape for blockchain and decentralized applications is constantly evolving. Platforms must remain compliant with data privacy regulations (e.g., GDPR, CCPA) and financial transaction laws while operating across multiple jurisdictions.
Networks Involved in Cross-Aggregation
VYGA will aggregate selected content and data across the following blockchain networks:
- Hedera (HBAR) done/in progress
- Ethereum (ETH) done/in progress
- Polygon (MATIC) done/in progress
- Immutable (IMX) done/in progress
- Binance (BNB) later/next stage
- Solana (SOL) later/next stage
During the THA supported MVP development VYGA starts by aggregating content explicitly from the approved platforms: Hashaxis, Superrare, Rarible.
Functional and Non-Functional Requirements
Functional Requirements
- Secure User Authentication and Authorization: Requirement: Implement secure user authentication using 2-Factor Authentication (2FA) and OAuth 2.0. The platform must allow users to log in and access personalized content based on their roles within 3 seconds Measurable Outcome: Achieve a 95% success rate in user authentication under 3 seconds with no security breaches.
- Content Aggregation: Requirement: Aggregate content from the specified blockchain networks, ensuring data consistency and availability. The platform must support cross-network data aggregation with an uptime of 99.9% during business hours. Measurable Outcome: Maintain 99.9% uptime and ensure data from all networks is available within 5 minutes of a content request.
- Search and Filtering: Requirement: Provide users with advanced search and filtering capabilities, including the prioritization of HBAR results. The search functionality should return results within 2 seconds for 95% of queries. Measurable Outcome: Achieve a 95% success rate in delivering search results within 2 seconds.
- User Dashboard and Analytics: Requirement: Offer a user-friendly dashboard with real-time analytics and insights. The dashboard must display updated data within 1 second of user interaction for 95% of users. Measurable Outcome: Ensure dashboard data refreshes within 1 second for 95% of users.
- Robust API Integration: Requirement: Provide a robust API that enables seamless interaction with third-party services. The API should process requests within 2 seconds for 95% of API calls. Measurable Outcome: Achieve a 95% success rate in processing API requests within 2 seconds.
Non-Functional Requirements
- Performance and Responsiveness: Requirement: Ensure the platform responds to user actions within 1 second for 95% of interactions, providing a smooth and efficient user experience. Measurable Outcome: Achieve 95% of user interactions completed within 1 second.
- Scalability: Requirement: Design the system to accommodate a 10x increase in the user base without requiring major architectural changes. The platform must support scaling without downtime or performance degradation. Measurable Outcome: Support a 10x increase in users while maintaining performance standards.
- Security and Compliance: Requirement: Implement data encryption both at rest and in transit, and ensure compliance with GDPR, CCPA, and financial transaction regulations. Regular security audits and penetration testing must be conducted to maintain compliance. Measurable Outcome: Achieve 100% compliance with security and data privacy regulations, with no reported breaches.
- Reliability: Requirement: Achieve 99.9% uptime during business hours, ensuring high availability and reliability for all users. Measurable Outcome: Maintain 99.9% uptime, with any downtime incidents resolved within 30 minutes.
- Maintainability and Testability:Requirement: Design the system with modular components to facilitate easy updates and maintenance. Aim for 80% code coverage with automated tests to ensure high code quality and reliability. Measurable Outcome: Achieve 80% code coverage in automated tests, with all updates and maintenance tasks completed within scheduled maintenance windows.
Quality Goals with Measurable Criteria
- Performance:Goal: Ensure the platform responds within 1 second for 95% of user requests. Measurable Criteria: Response Time Monitoring: Implement real-time monitoring to track response times, with alerts triggered if more than 5% of requests exceed the threshold. Optimization: Use caching strategies and content delivery networks (CDNs) to reduce latency. Load Testing: Conduct regular load testing to ensure efficient performance under expected and peak loads.
- Security: Goal: Ensure the platform responds within 1 second for 95% of user requests. Measurable Criteria: Response Time Monitoring: Implement real-time monitoring to track response times, with alerts triggered if more than 5% of requests exceed the threshold. Optimization: Use caching strategies and content delivery networks (CDNs) to reduce latency. Load Testing: Conduct regular load testing to ensure efficient performance under expected and peak loads.
- Scalability: Goal: Support a 10x increase in the user base without major changes to the architecture. Measurable Criteria: Scalability Testing: Conduct stress testing to simulate a 10x increase in user traffic. Horizontal Scaling: Design the architecture for horizontal scaling using cloud services. Modular Architecture: Implement a modular monolith or microservices architecture to allow independent scaling of components.
- Reliability: Goal: Achieve 99.9% uptime during business hours (9 AM to 6 PM, Monday to Friday). Measurable Criteria: Uptime Monitoring: Utilize real-time monitoring to track uptime. Incident Response: Set up automated incident response with alerts and ensure resolution within 30 minutes. Redundancy: Implement failover strategies and redundancy at both the application and infrastructure levels.
- Compliance: Goal: Maintain compliance with relevant data privacy and financial transaction regulations. Measurable Criteria: Automated Compliance Checks: Implement continuous compliance monitoring to ensure adherence to regulations. Data Handling Procedures: Document and review data handling processes regularly. Auditable Logs: Maintain auditable logs of all transactions and data access events.
- Maintainability: Goal: Ensure the system is maintainable with a modular design and clear documentation. Measurable Criteria: Modularity: Design the system with clear separation of concerns for easier updates and maintenance. Code Documentation: Maintain comprehensive documentation and architectural diagrams. Dependency Management: Keep dependencies up-to-date using tools like Poetry for Python and npm for JavaScript.
- Testability: Goal: Achieve 80% code coverage by automated tests. Measurable Criteria: Unit Testing: Ensure all new code is accompanied by unit tests, aiming for 80% code coverage. Integration Testing: Develop automated integration tests covering critical interactions, with nightly test runs. Continuous Testing: Integrate testing into the CI/CD pipeline, with automatic blocking of builds that fail to meet the required test coverage.
Key Features and Benefits
Project VYGA includes various features that make it a unique endeavor. Below an overview of most relevant features, all of which are to be implemented during the MVP. Future features have not been included in this overview. For more detailed information, including (1) grouping of features, (2) explicit target groups and (3) feature prioritization, please consult the VYGA - KEY FEATURE DOC.
- Simplified interaction with multiple content networks.
- Reduced operational costs for clients.
- Enhanced security and compliance through blockchain integration.
- Flexible pricing based on transaction volume.
- Free implementation for developers to encourage adoption.
- AI-supported content curation and search optimization.
- Prioritization of HBAR results in search functionalities.
- Rebranding and improved UI for better user experience.
Technical Aspects
Technologies to be Used
Project VYGA includes various technologies, all of which are listed below. For more detailed information, please consult the structured Architecture Decision Records (ADRs): VYGA - ADR DOC.
- Backend: Python with Flask framework.
- Frontend: React for a Single Page Application (SPA).
- Database: MongoDB using Atlas for cloud-hosted database management.
- AI and Data Processing: Python libraries such as Pandas, NumPy, and Scikit-learn. Use TensorFlow or PyTorch for AI model training and deployment.
- Containerization: Docker for containerizing applications.
- Orchestration: AWS ECS (Elastic Container Service) for managing and deploying containers.
- Container Registry: AWS ECR (Elastic Container Registry) for storing Docker images.
- CI/CD: Jenkins, GitHub Actions, or GitLab CI/CD for continuous integration and deployment pipelines.
- Infrastructure as Code (IaC): Terraform or AWS CloudFormation for managing infrastructure provisioning and configuration.
- Search Engine: Elasticsearch for implementing advanced search functionalities and indexing the aggregated content.
- Task Queue: Celery for handling background tasks and asynchronous processing.
- Blockchain Integration: Hedera blockchain for secure transactions and integration with Hashpack wallet.
Backend Development
The backend will be developed using Flask, a micro web framework written in Python. Flask is lightweight and flexible, making it ideal for developing APIs and backend services.
The backend will expose RESTful APIs to interact with the frontend and other services. These APIs will handle user authentication, content aggregation, search functionalities, and AI-supported processes.
Python libraries like Pandas and NumPy will be used for data manipulation and analysis. TensorFlow or PyTorch will be utilized for developing and deploying AI models for content curation and search optimization.
Frontend Development
The frontend will be developed using React, which allows for the creation of dynamic and responsive user interfaces. The SPA will interact with the backend APIs to provide users with real-time content updates and search capabilities.
Database Management
MongoDB Atlas will be used for managing the database. MongoDB is a NoSQL database that provides high performance, high availability, and easy scalability.
All persistent data, including user information, content records, and billing details, will be stored in MongoDB. The database will be designed to handle large volumes of data efficiently.
AI Model Training and Deployment
AI models for content curation and search optimization will be developed using TensorFlow or PyTorch. These models will be trained on historical data and deployed on AWS for scalability and performance.
Containerization and Orchestration
All services will be containerized using Docker to ensure consistency across different environments. Docker allows for easy scaling and deployment of applications.
AWS Elastic Container Service will be used for orchestrating and managing Docker containers. ECS provides a scalable and secure way to run containerized applications in production.
AWS Elastic Container Registry will be used to store Docker images. ECR integrates seamlessly with ECS, allowing for smooth deployment workflows.
Security and Compliance
- TLS Encryption: All external communications will be encrypted using TLS 1.3 to ensure data security.
- OAuth 2.0 and JWT: API authentication will be handled using OAuth 2.0 with JWT tokens to provide secure access.
- Data Encryption: Sensitive data in MongoDB will be encrypted at rest and in transit.
- Security Audits: Regular security audits and penetration testing will be conducted to identify and mitigate vulnerabilities.
Monitoring and Logging
- Centralized Logging: The ELK stack (Elasticsearch, Logstash, Kibana) will be used for centralized logging. This allows for efficient monitoring and troubleshooting of the platform.
- Metrics Collection: Prometheus will be used for metrics collection, and Grafana will be used for visualization. This will provide insights into the performance and health of the system.
- Automated Alerts: An automated alerting system will be implemented to notify the team of critical issues in real-time.
Architecture
System Context View
The System Context Diagram provides an overview of the VYGA platform, illustrating how it interacts with external systems and users. Actors: End User: Individuals or brands accessing the VYGA platform to discover and interact with curated Web3 content. Admin User: System administrators managing the platform's content and user roles. Third-Party Service Providers: Providers offering content, blockchain networks, and authentication services (OAuth 2.0, Hedera blockchain, Hashpack wallet). External Systems: Blockchain: Hedera blockchain for secure transactions. Blockchain Networks: Source of digital collectibles, digital art, Web3 gaming, and Metaverse projects. OAuth 2.0 Provider: External service for user authentication. External APIs: External APIs including payment providers.
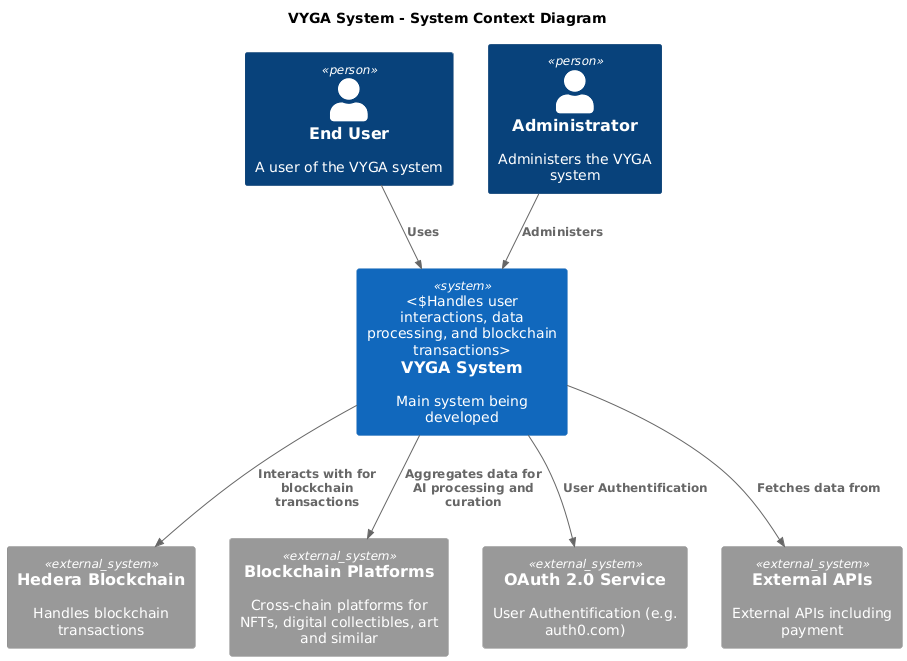
Figure 1: System Context Diagram of VYGA Platform
Container View
This container diagram shows the main components of the VYGA platform and their interactions:
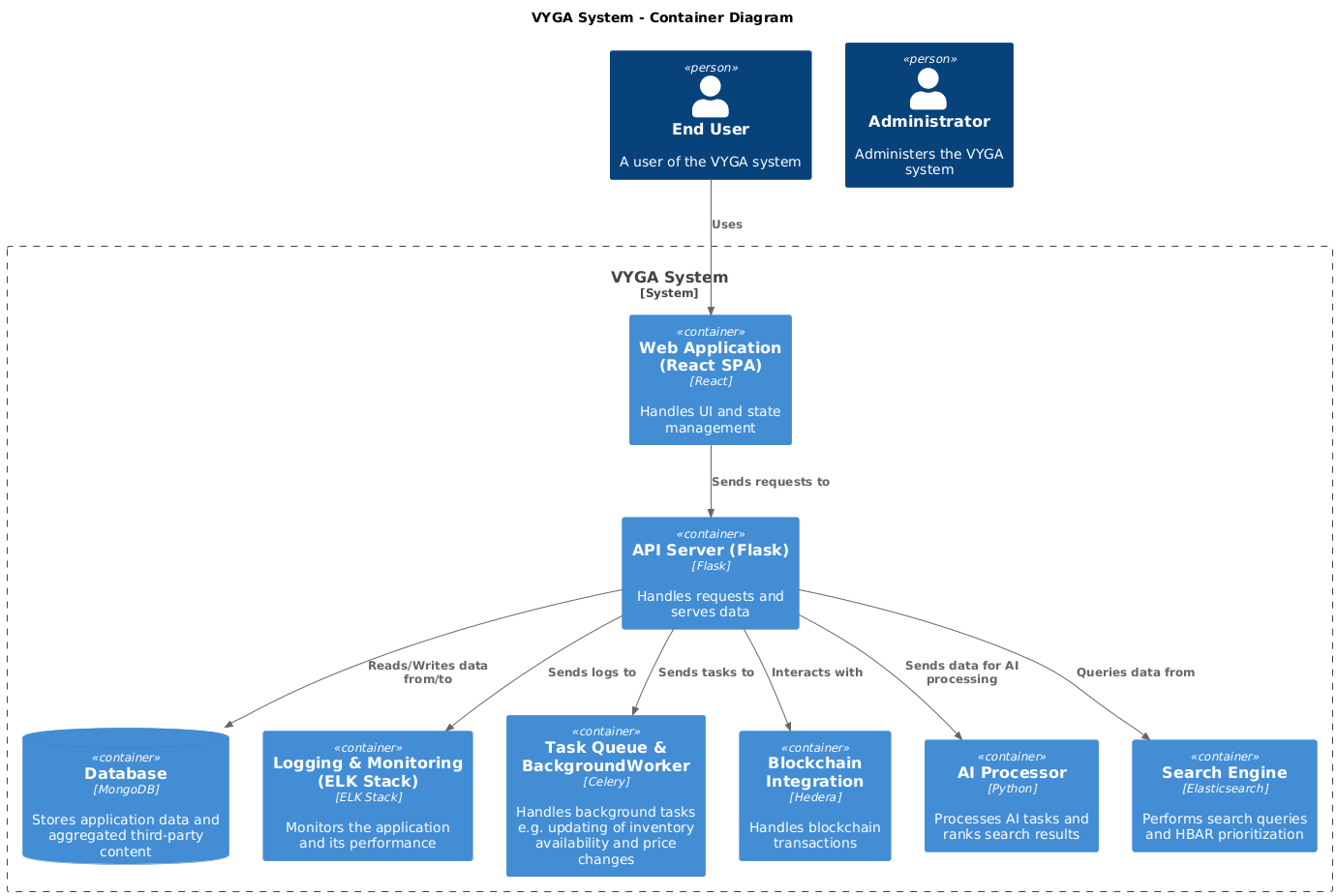
Figure 2: Container Diagram of VYGA Platform
VYGA System: Frontend (React SPA): The user interface through which end users and admins interact with the platform. Backend (Flask API): The core application logic that handles user authentication, content aggregation, and data processing. Database (MongoDB Atlas): Storage for all platform data, including user information, content, and transaction logs. AI Processing (TensorFlow/PyTorch): AI components that curate content and optimize search results. Search Engine (Elasticsearch): Facilitates advanced search and filtering capabilities. Monitoring and Logging (ELK Stack, Prometheus, Grafana): Tools for monitoring platform performance and logging system activities.
Component Diagrams
Component Diagram: Web Application
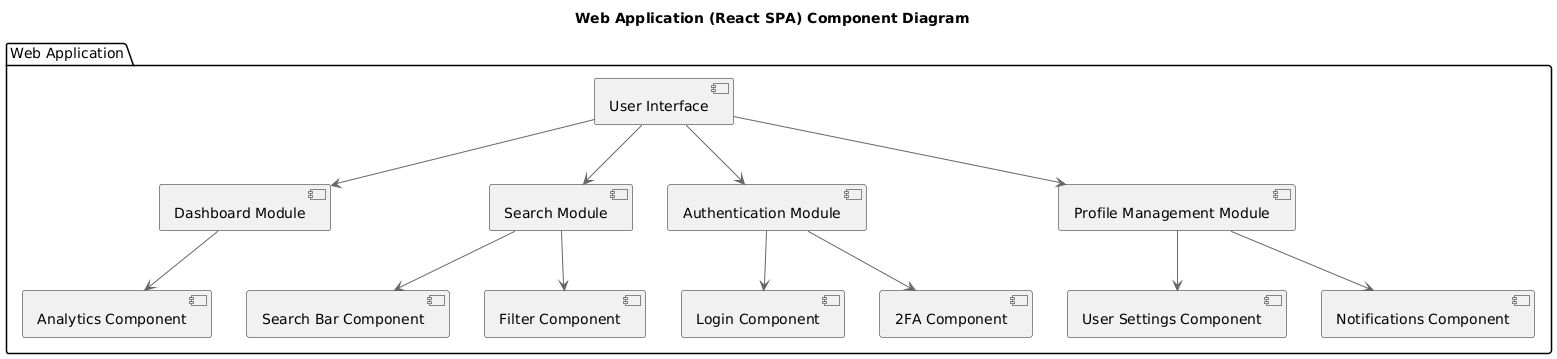
Figure 3: Component Diagram: Web Application This diagram describes the structure of the React-based frontend, detailing its key modules.
Component Diagram: API Server
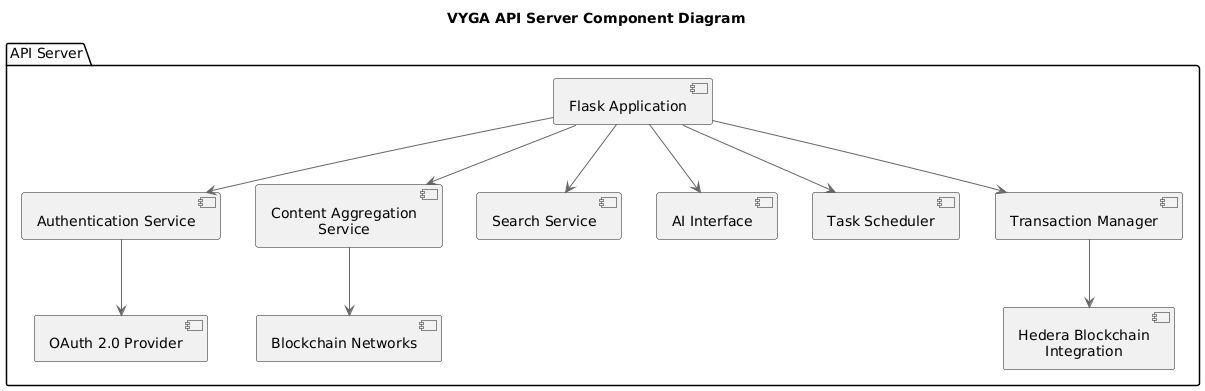
Figure 4: Component Diagram: API Server This diagram will focus on the components within the API Server, which is the core of the backend.
Component Diagram: Database
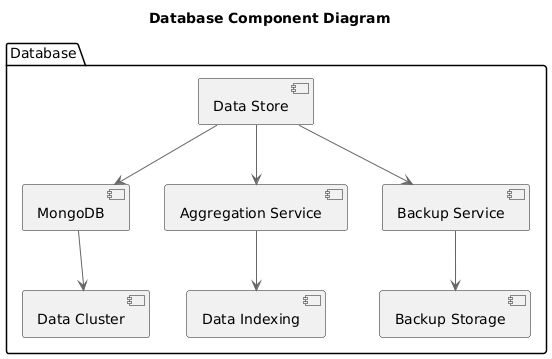
Figure 5: Component Diagram: DatabaseThis diagram illustrates the components involved in data storage, aggregation, and backup processes within the MongoDB-based database system.
Component Diagram: Logging & Monitoring
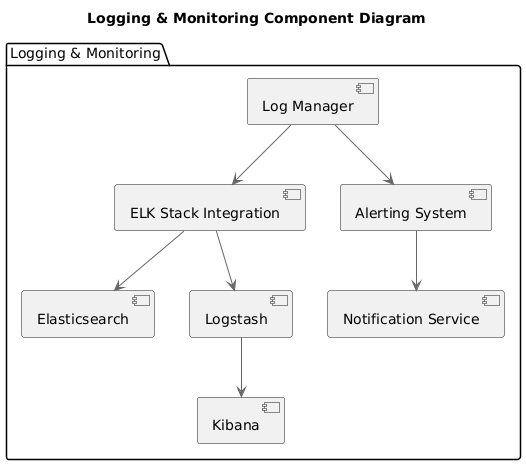
Figure 6: Component Diagram: Logging & MonitoringThis diagram shows the components responsible for logging, monitoring, and alerting using the ELK Stack and associated services.
Component Diagram: Task Queue
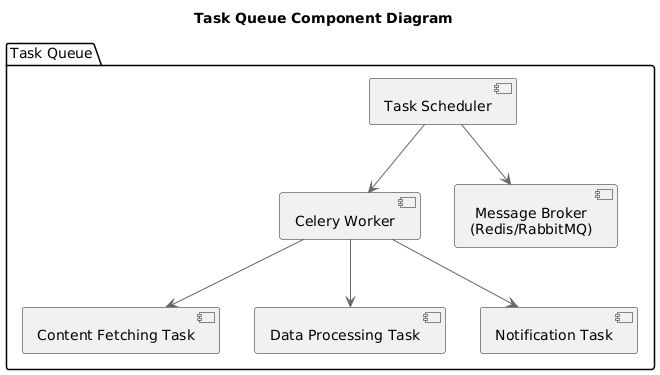
Figure 7: Component Diagram: Task QueueThis diagram details the tasks managed by the Celery task queue, focusing on how different background tasks are handled..
Component Diagram: Blockcahin Integration
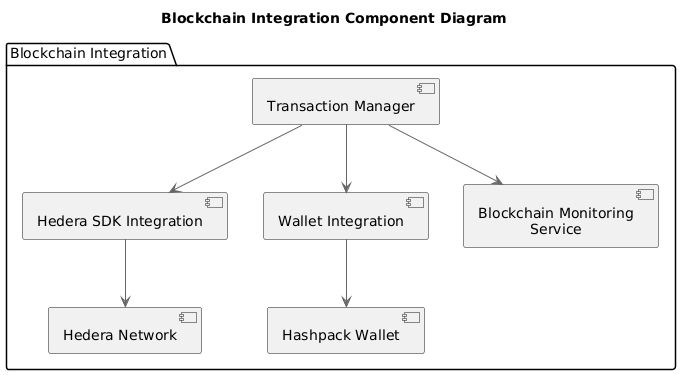
Figure 8: Component Diagram: Blockchain IntegrationThis diagram focuses on how the system integrates with the Hedera blockchain and Hashpack wallet for secure transactions.
Component Diagram: AI Processor
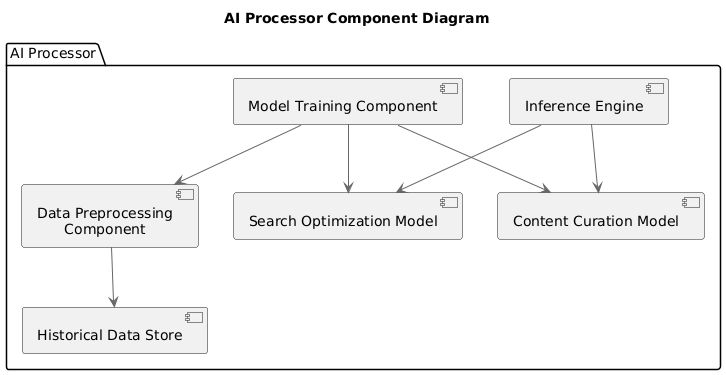
Figure 9: Component Diagram: AI ProcessorThis diagram focuses on the components within the AI Processor, which handles the AI models for content curation and search optimization.
Component Diagram: Search Engines
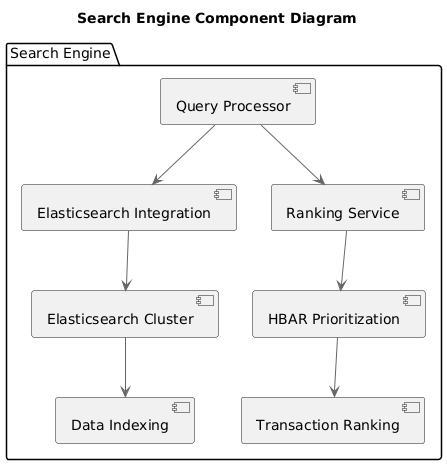
Figure 10: Component Diagram: Search EngineThis diagram represents the components involved in processing search queries, integrating with Elasticsearch, and prioritizing results using HBAR.
Deployment Diagram
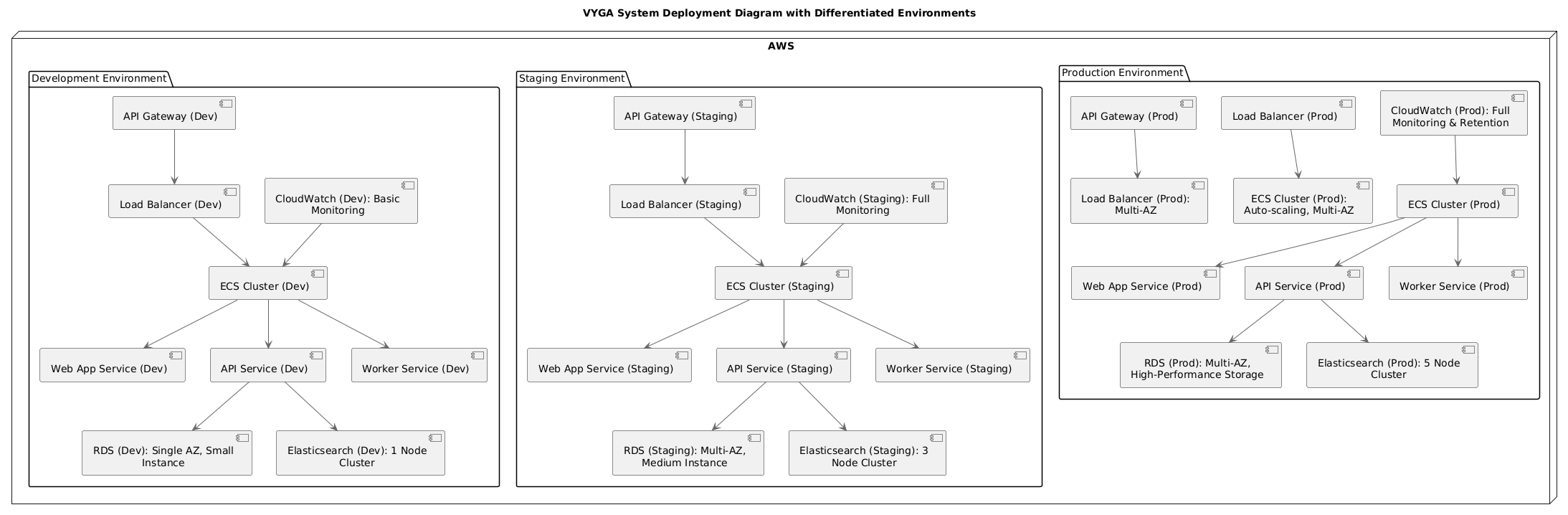
Figure 11: Deployment Diagram This diagram represents the deployment architecture of the VYGA system across three distinct environments: Development, Staging, and Production, all hosted on AWS. It illustrates how key AWS resources such as API Gateway, Elastic Load Balancers, ECS (Elastic Container Service) Clusters, RDS (Relational Database Service) instances, and Elasticsearch clusters are utilized and interact within each environment. Additionally, the diagram shows the flow of requests, data storage, and monitoring/logging operations using CloudWatch, ensuring clear visibility into the deployment and operational flow for each environment. These resources are scaled appropriately depending on the environment, with production being fully scaled for high availability and performance, while development and staging environments are configured with smaller, cost-effective resources.
UML Diagrams
Sequence Diagram: Secure User Authentication and Authorization
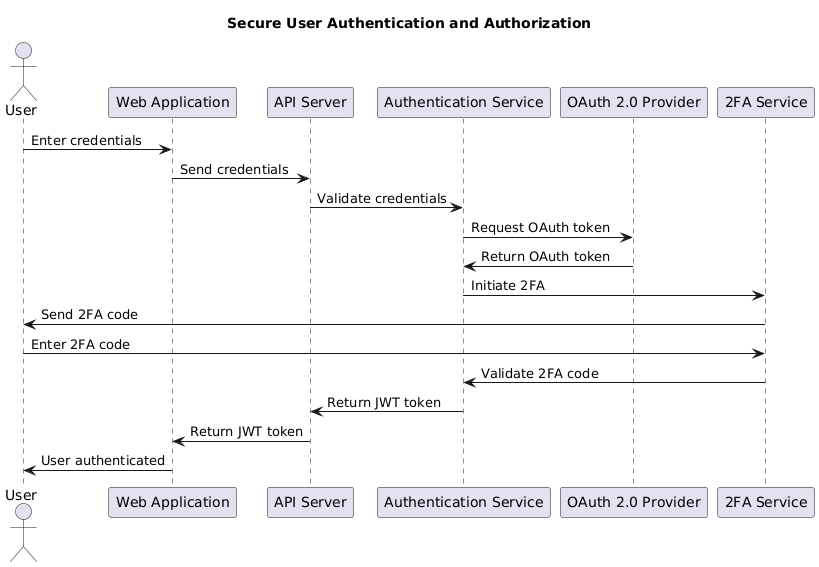
Figure 12: Sequence Diagram: Secure User Authentication and Authorization This sequence diagram describes the process of user authentication using 2FA and OAuth 2.0.
Sequence Diagram:Content Aggregation
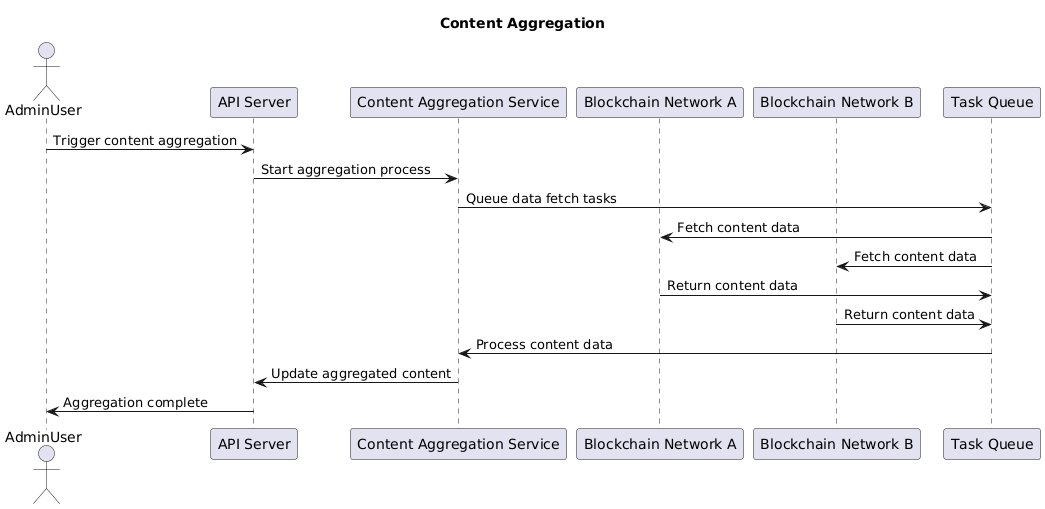
Figure 13: Sequence Diagram: Content Aggregation This sequence diagram shows the process of aggregating content from various blockchain networks.
Sequence Diagram: Search & Filtering
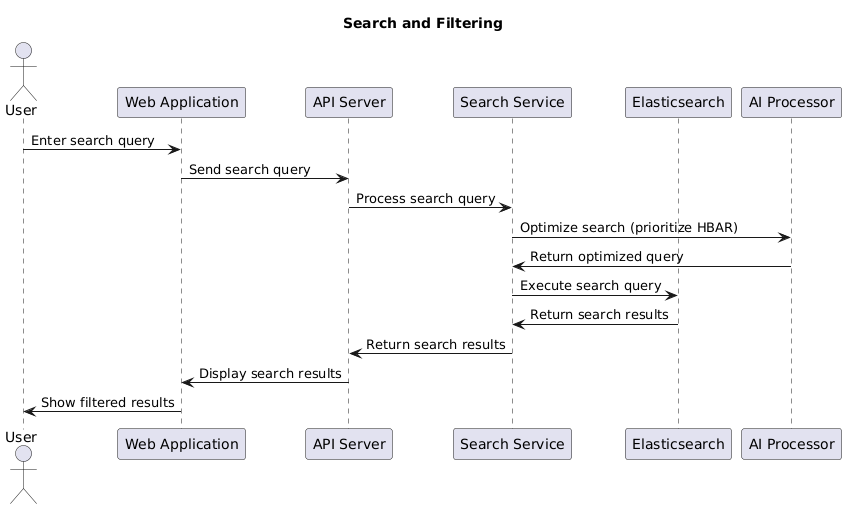
Figure 14: Sequence Diagram: Search & FilteringThis sequence diagram describes the process of searching and filtering content, with prioritization of HBAR results.
Sequence Diagram: User Dashboard & Analytics
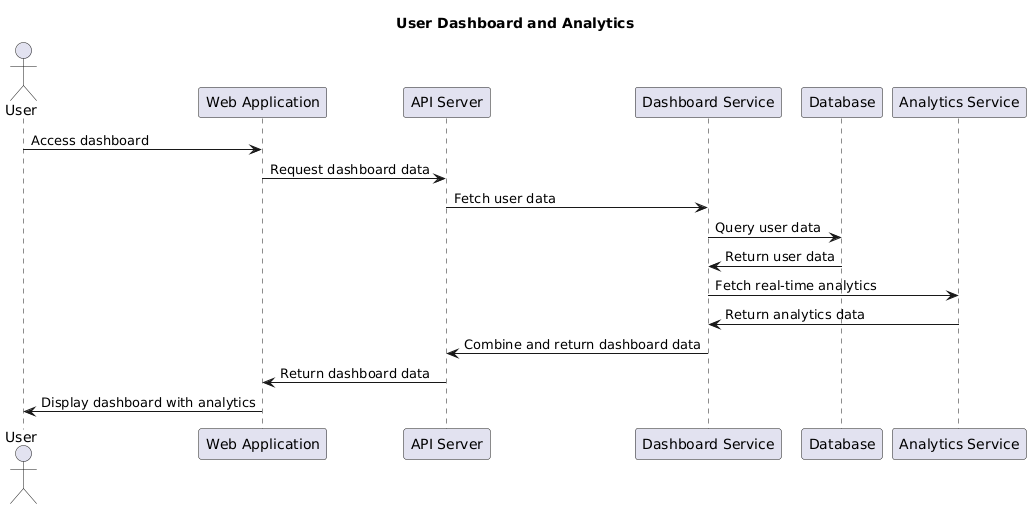
Figure 15: Sequence Diagram: User Dashboard & AnalyticsThis sequence diagram covers the interactions that occur when a user accesses the dashboard and views real-time analytics.
Sequence Diagram: Robust API Integration
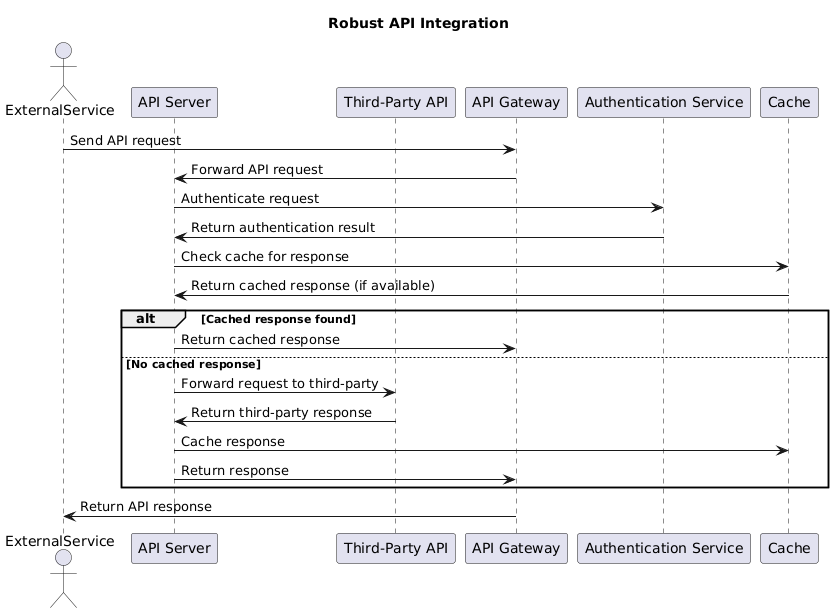
Figure 16: Sequence Diagram: Robust API IntegrationThis sequence diagram illustrates the process of API calls to third-party services, focusing on ensuring the interaction is seamless and meets performance requirements.
Activity Diagram: Transaction Process
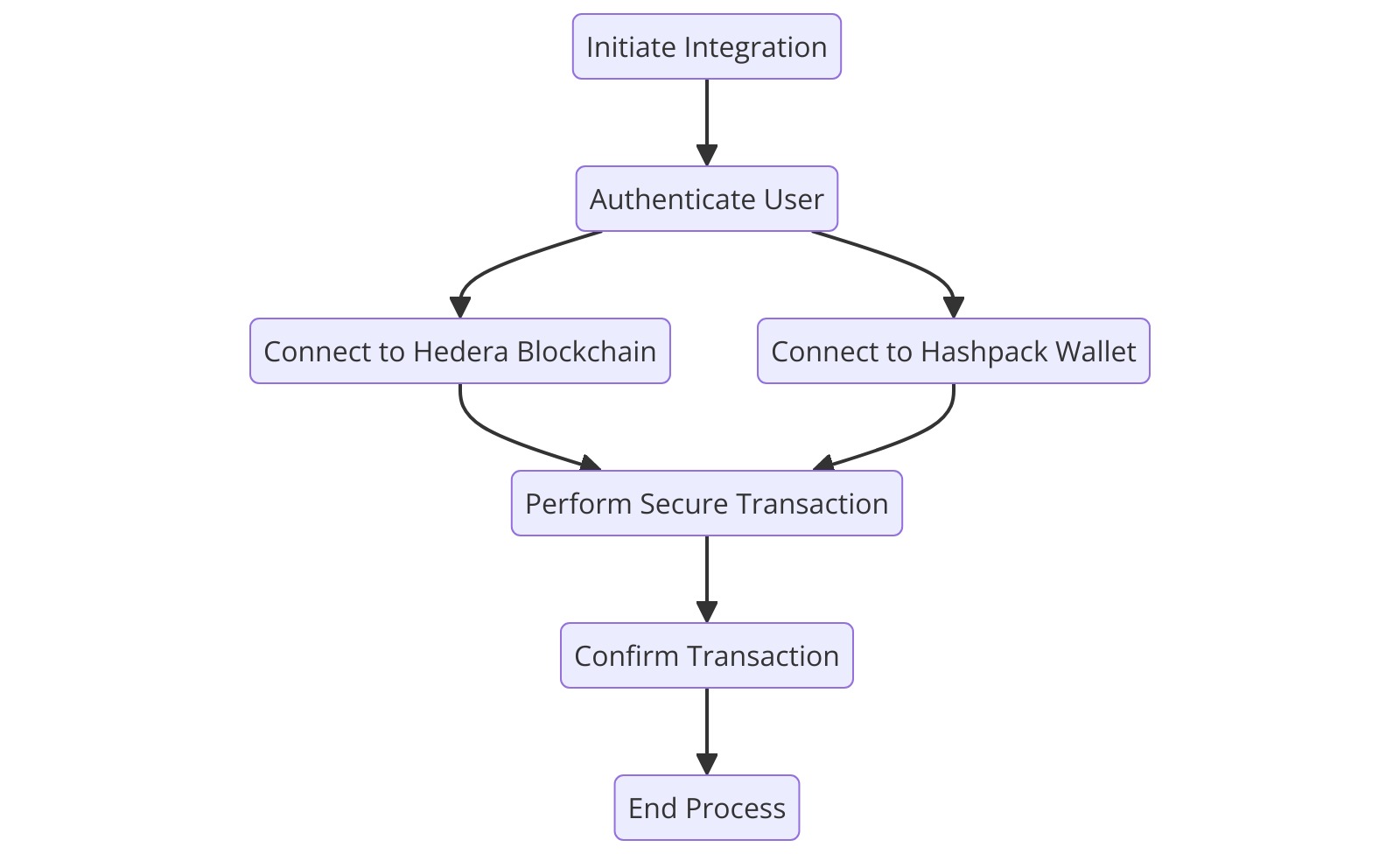
Figure 17: Activity Diagram: Transaction Process
Activity Diagram: AI Model Training and Deployment
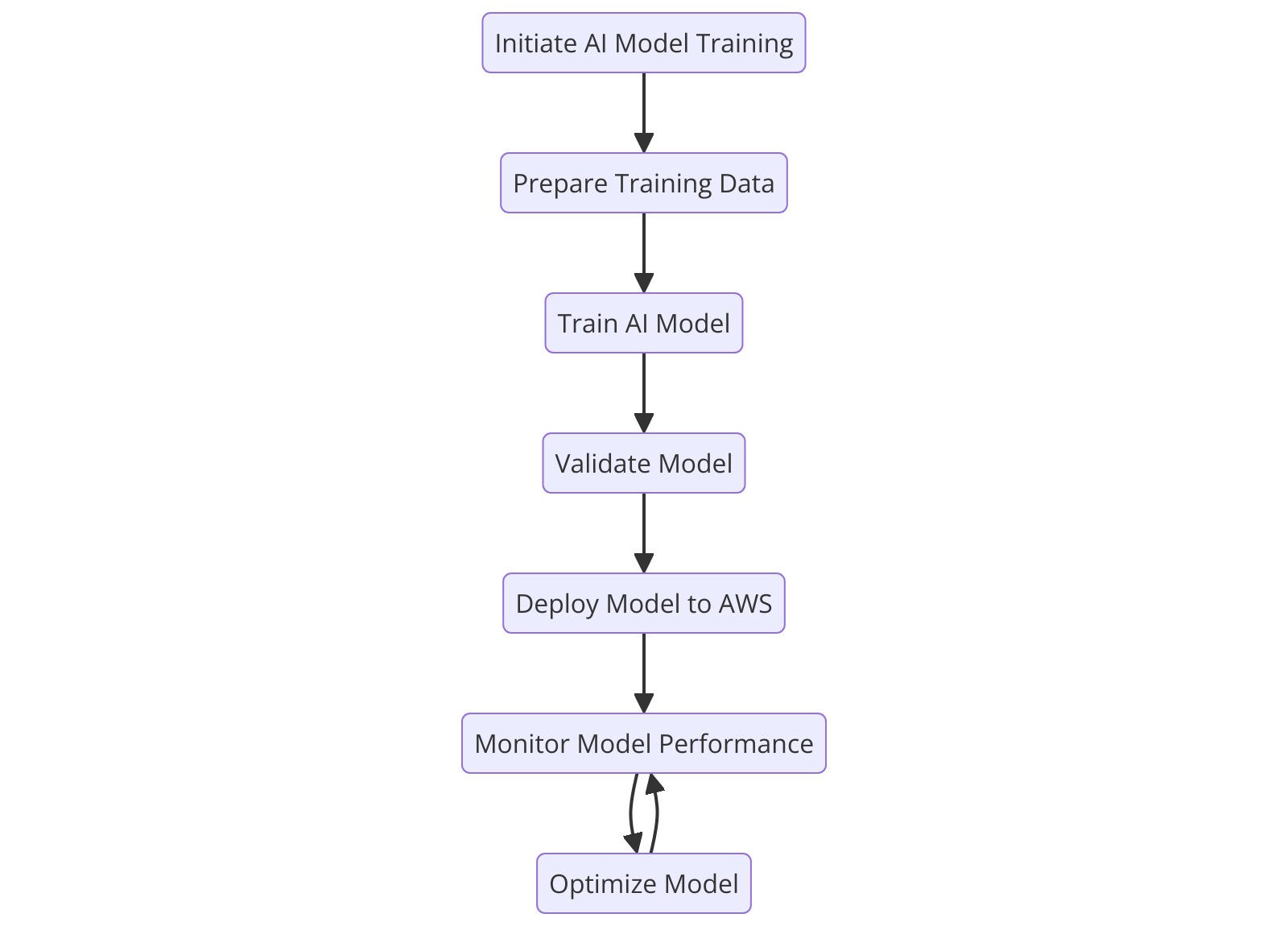
Figure 18: Activity Diagram: AI Model Training and Deployment
Activity Diagram: AI Model Training and Deployment Process
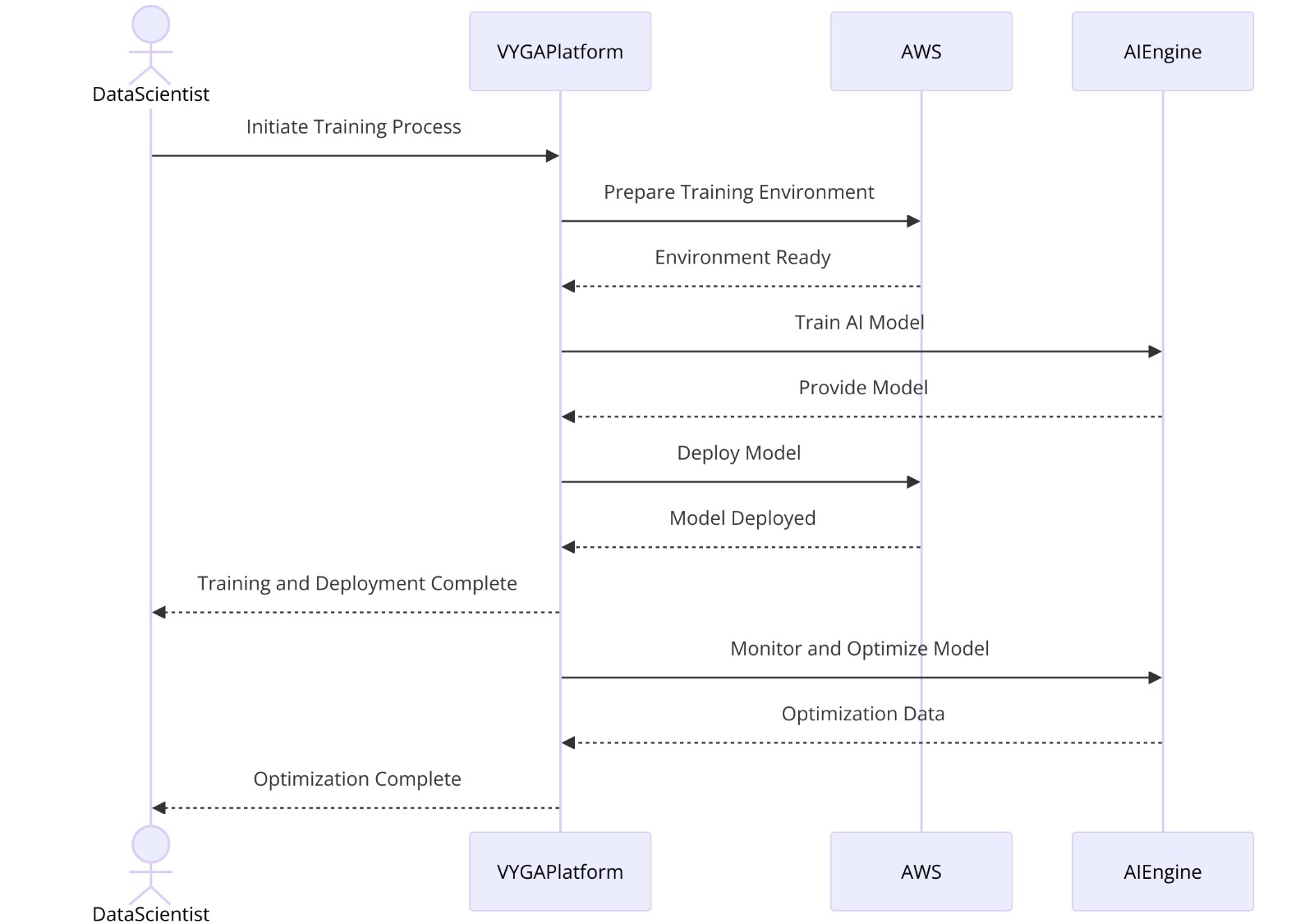
Figure 19: Activity Diagram: AI Model Training and Deployment Process
Activity Diagram: User Transaction with Hedera and Hashpack
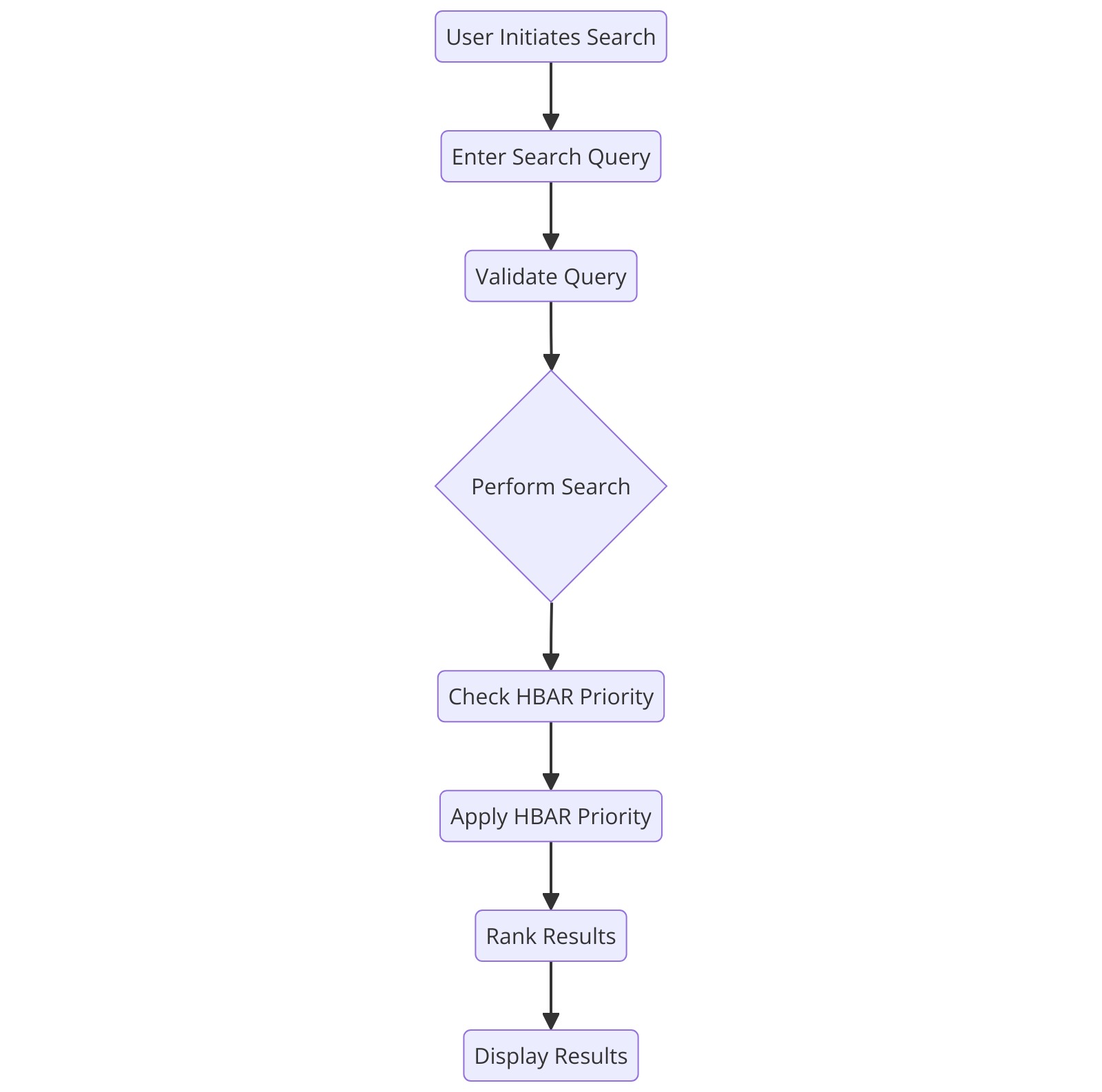
Figure 20: Activity Diagram: User Transaction with Hedera and Hashpack
User Journey
The user journey describes the steps and experiences a user goes through while interacting with the VYGA platform. For detailed information, please refer to the User Journey Document.
MVP Code
1. Aggregate Selected Content from Different Networks
# content_aggregator.py
import requests
from pymongo import MongoClient
def aggregate_content():
networks = ['network1', 'network2', 'network3']
client = MongoClient('mongodb://localhost:27017/')
db = client.vyga
content_collection = db.content
for network in networks:
response = requests.get(f'http://api.{network}.com/content')
if response.status_code == 200:
content = response.json()
content_collection.insert_many(content)
if __name__ == "__main__":
aggregate_content()
2. Enable Users to Find Content (Search Function)
# search_service.py
from flask import Flask, request, jsonify
from elasticsearch import Elasticsearch
app = Flask(__name__)
es = Elasticsearch(['http://localhost:9200'])
@app.route('/search', methods=['GET'])
def search_content():
query = request.args.get('q')
response = es.search(
index="content",
body={
"query": {
"multi_match": {
"query": query,
"fields": ["title", "description", "tags"]
}
}
}
)
return jsonify(response['hits']['hits'])
if __name__ == "__main__":
app.run(debug=True)
3. Develop AI-Supported Functionalities
# ai_functions.py
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
def update_content_model():
client = MongoClient('mongodb://localhost:27017/')
db = client.vyga
content_collection = db.content
content = list(content_collection.find())
df = pd.DataFrame(content)
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(df['description'])
model = KMeans(n_clusters=5, random_state=42)
model.fit(X)
df['cluster'] = model.labels_
for index, row in df.iterrows():
content_collection.update_one({'_id': row['_id']}, {'$set': {'cluster': row['cluster']}})
if __name__ == "__main__":
update_content_model()
4. Integrate with Hedera Blockchain and Hashpack Wallet
# hedera_integration.py
from hedera import Hbar, AccountId, PrivateKey, Client
from hedera import Transaction, TransactionReceiptQuery
def create_hedera_transaction(amount, sender_account_id, receiver_account_id, private_key):
client = Client.forTestnet()
client.setOperator(AccountId.fromString(sender_account_id), PrivateKey.fromString(private_key))
transaction = Transaction.newTransferTransaction()
transaction.setSenderAccountId(AccountId.fromString(sender_account_id))
transaction.setReceiverAccountId(AccountId.fromString(receiver_account_id))
transaction.setAmount(Hbar(amount))
transaction.freezeWith(client)
transaction.signWith(PrivateKey.fromString(private_key))
tx_id = transaction.execute(client)
receipt = TransactionReceiptQuery(tx_id).execute(client)
return receipt.status
if __name__ == "__main__":
sender = "0.0.1234"
receiver = "0.0.5678"
private_key = "302e020100300506032b657004220420..."
amount = 10
status = create_hedera_transaction(amount, sender, receiver, private_key)
print(f'Transaction status: {status}')
5. Train and Deploy AI Models on AWS
# ai_training.py
import boto3
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
def train_model():
# Load and preprocess data
client = MongoClient('mongodb://localhost:27017/')
db = client.vyga
content_collection = db.content
content = list(content_collection.find())
df = pd.DataFrame(content)
X_train, X_test, y_train, y_test = train_test_split(df['description'], df['label'], test_size=0.2, random_state=42)
# Create and train model
model = tf.keras.Sequential([
tf.keras.layers.TextVectorization(input_shape=(1,), output_mode='tf-idf'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
# Save and upload model to S3
model.save('vyga_model.h5')
s3 = boto3.client('s3')
s3.upload_file('vyga_model.h5', 'vyga-models', 'vyga_model.h5')
if __name__ == "__main__":
train_model()
6. Prioritize HBAR Results in Searches
# search_service.py (update)
@app.route('/search', methods=['GET'])
def search_content():
query = request.args.get('q')
response = es.search(
index="content",
body={
"query": {
"multi_match": {
"query": query,
"fields": ["title", "description", "tags"]
}
},
"sort": [
{"token": {"order": "desc", "missing": "_last"}}
]
}
)
return jsonify(response['hits']['hits'])
7. Implement Rebranding Requirements for the User Interface (UI)
// App.js (React)
import React from 'react';
import './App.css';
function App() {
return (
<div className="App">
<header className="App-header">
<h1>Welcome to VYGA</h1>
</header>
<main>
<p>Discover the best of Web3.</p>
<button>Explore</button>
</main>
</div>
);
}
export default App;
8. Ensure Compliance with Data Privacy Regulations and Financial Transaction Laws
# compliance_check.py
import requests
def check_gdpr_compliance(data):
response = requests.post('https://gdpr-check-api.com/validate', json=data)
return response.json()
def check_transaction_compliance(transaction):
response = requests.post('https://transaction-check-api.com/validate', json=transaction)
return response.json()
if __name__ == "__main__":
user_data = {"name": "John Doe", "email": "john@example.com"}
transaction_data = {"amount": 100, "currency": "USD"}
gdpr_status = check_gdpr_compliance(user_data)
transaction_status = check_transaction_compliance(transaction_data)
print(f'GDPR Compliance: {gdpr_status}')
print(f'Transaction Compliance: {transaction_status}')
Cross-Cutting Concepts
An overview of cross-cutting concepts of project VYGA including specific implementation strategies and tools can be found in following document: VYGA - CROSS-CUTTING CONCEPTS.
Risks and Technical Debt
Risks
- Database Down or Not Updated in Real-Time Mitigation: Implement a redundant database setup with failover mechanisms to ensure continuous availability; use real-time database replication to keep backup databases synchronized with the primary database; set up automated monitoring and alert systems to quickly detect and respond to database downtime or synchronization issues
- Faulty Integration of Third-Party Content Mitigation: Conduct extensive testing in a staging environment before integrating third-party content into the production system; ensure clear API contracts and comprehensive documentation are provided by third-party content providers to minimize integration errors; implement detailed monitoring and logging for all third-party integrations to quickly identify and rectify any issues
- Hedera Network Downtime: Inability to process transactions if Hedera is down. Mitigation: Implement a queuing system for transactions
- Low Speed of Transaction Mitigation: Optimize Smart Contracts and regularly review and optimize smart contracts for efficiency to reduce execution time and costs; use load balancing techniques to distribute transaction processing across multiple nodes in the Hedera network; implement scalability solutions like sharding or layer-2 scaling to handle higher transaction volumes efficiently; continuously monitor transaction performance and identify bottlenecks to be addressed proactively.
- Security Vulnerabilities: Potential for security breaches. Mitigation: Conduct regular security audits and keep dependencies updated.
Technical Debt
- Manual Testing Bottlenecks: Integrate continuous testing into the continous Integration (CI) pipeline to catch issues early in the development cycle
- Testing Gaps in AI Algorithms: Develop comprehensive testing and validation procedures for AI algorithms to ensure they deliver accurate and reliable results
- Query Optimization: Optimize database queries and use indexing to improve data retrieval speed and efficiency
- Efficient AI Processing: Optimize AI algorithms and consider using specialized hardware or cloud-based AI services to improve processing efficiency
Scalability
The VYGA platform is designed to be scalable to handle increasing loads and a growing user base. Key scalability strategies include:
- Using Docker and ECS to easily scale microservices based on demand.
- Implementing auto-scaling policies on AWS to automatically adjust resources based on traffic and usage patterns.
- Using a NoSQL database like MongoDB, which can handle large volumes of data and scale horizontally.
- Employing load balancers to distribute traffic evenly across multiple instances of microservices.
- Optimizing performance through caching mechanisms and database indexing to handle high read and write loads efficiently.
Interoperability
Ensuring interoperability across different systems and networks is crucial for the VYGA platform. Strategies for achieving interoperability include:
- Adhering to RESTful API design principles to enable seamless integration with third-party services and applications.
- Using standard data formats such as JSON and XML for data exchange between different systems.
- Implementing API gateways to manage and route API requests efficiently, providing a unified interface for external integrations.
- Ensuring compliance with industry standards and protocols to facilitate smooth interactions with other platforms and networks.
- Providing comprehensive API documentation and support to assist developers in integrating their applications with the VYGA platform.